
Around the time that our data infrastructure was starting to mature, Girl Effect was sub-awarded a Bill and Melinda Gates Foundation grant to write a public report about the use of natural language processing (NLP) and other types of AI and ML in family planning chatbots – Girl Effect is well-known for having implemented BERT-based classification models in its flagship chatbot, South Africa-based Big Sis, from as early as 2018. The award was granted before the advent of ChatGPT in late 2022 but in the aftermath of the large language model explosion, the grant became increasingly important and timely. At the time, I had the most relevant technical background, having majored in a technical field and minored in Mathematics, and despite having no prior experience in NLP, I dove into the literature and mapped out the several ways that this LLM revolution could be used to better the delivery and user experience of family planning chatbots. On top of mapping this out, I developed multiple proofs of concept for a generative AI-driven Big Sis in Python using Girl Effect’s content and OpenAI API tutorials – these POCs were able to demonstrate the transformative potential of generative AI in creating more personalized, relatable user experiences, easing access to life-saving information and services. The resultant report, Girl Effect’s Artificial Intelligence and Machine Learning Vision for Family Planning Chatbots (authored by me), laid out not just the current landscape of NLP but also key techniques underpinning the most famous models of the time. It served as both an educational tool for non-technical audiences in the international development space who were looking to understand what these new technologies meant for international development and a reference guide for ICT4D (information and communication technologies for development) organizations who were hoping to apply the power of LLMs to new features that could benefit a wide range of development projects ranging from educational tools to process efficiencies to new evaluation methods.
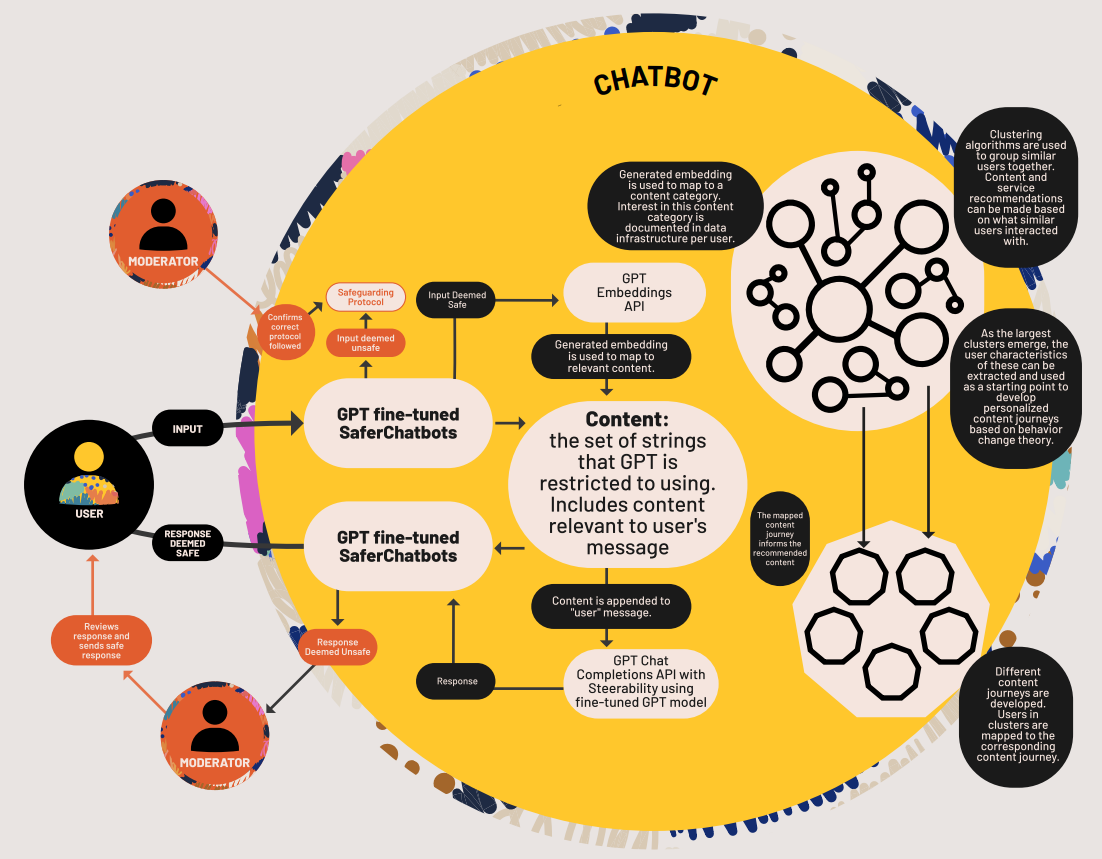
Architecture diagram of next generation chatbot developed for Girl Effect's vision paper.
The future vision laid out in the document also served as a launchpad for new funds donated by a series of individuals and organizations who were inspired by the vision set forth and invested in bringing it to reality. This initial source of new funding allowed our team to go from prototype to production. Over the past year and a half, I have led a 10-person team of data scientists, software engineers, ML engineers, data curators, and UX designers to develop, evaluate, and deploy generative AI features including direct question-answering and mix-coded language classification at scale and set up several further proofs of concept including generative-AI enabled conversational experiences that can guide users through mental wellbeing content and social and behavior change content. This work has involved developing a comprehensive evaluation framework that can evaluate our AI system at every decision step it takes on metrics like safety, reliability, and cultural relevance and managing the development of an infrastructure that is model-agnostic, capable of using existing highly-performant models and hosting our own custom models. Due to how relatively recently generative AI has become technologically and financially accessible to a broader set of users, much of our work has been research and development – we tested existing early frameworks but largely had to build our own custom evaluation framework, develop detection thresholds and set our own standards for use case-specific metrics like the tone of a generated message. We deployed our first generative AI features in an A/B test (randomized control trial) to evaluate the real impact of generative AI. I performed the statistical evaluation: users who experienced the generative AI question-answering feature were 11.24% more likely to recommend Big Sis, 17.1% more likely to engage with key messaging, 11.87% more likely to return to Big Sis, and 12.68% more likely to access vital service information – all statistically significant figures. To share our learnings and challenges with the broader sector, I wrote a follow-up whitepaper published in September 2025, describing our progress to date and outlining our updated vision for the future.
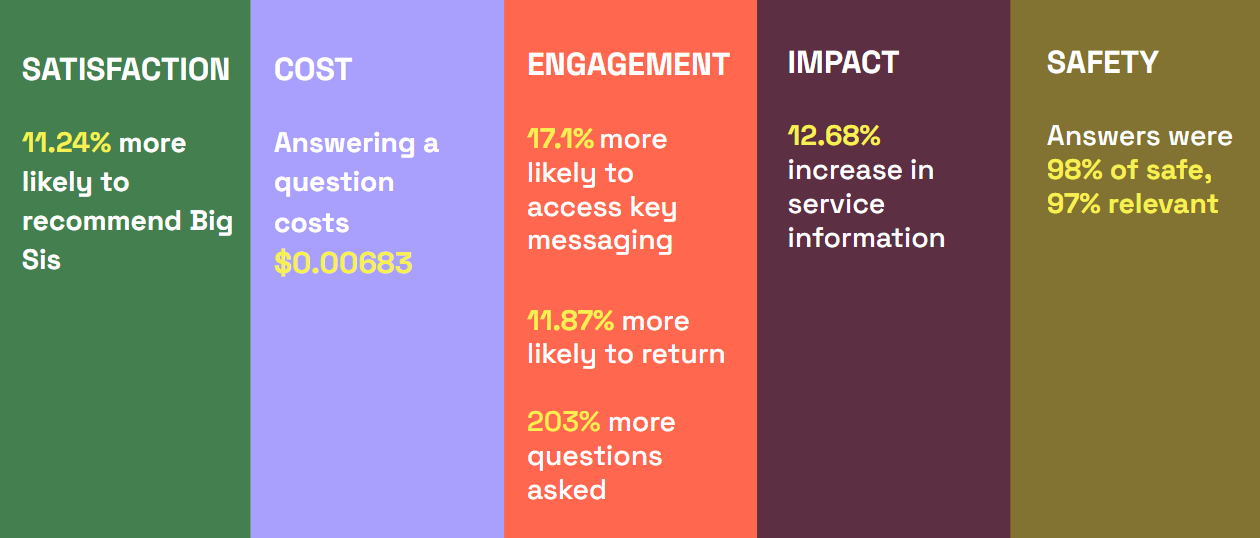
Results from the evaluation of our generative AI system in an A/B test.
Throughout this time, I have had the chance to train smaller language models myself, used clustering algorithms to understand our text data and user behavior data better, become very familiar with using existing LLMs for generation and analysis, and used embeddings to develop guardrails. In particular, I designed our “in-topic” guardrail that uses a series of decision steps, two based on embedding cosine similarity thresholds and one based on a prompt, to determine whether a user question should be answered or not based on how “close” the user input is semantically to our existing vetted content.
My experiences building Girl Effect’s AI system led to many new questions as we wrestled with these LLMs to do our bidding. I’d often find myself questioning what may be going on under the hood when simple LLM requests like checking whether two strings matched gave unreliable results but asking an LLM to categorize a user input as one of eight complex behavior drivers led our own human data curators to question their categorizations. I have many questions about the architecture of these models and the patterns they lead to and working with LLMs in non-Western contexts also started making me question whether it’s possible to ever be truly, 100% safe with no world model, no value system built in. Is it enough to simply throw more data at the LLM and assume it’ll adapt with no stronger guidance? Many of my experiences with prompt engineering – giving LLMs more or less complex instructions and documents – have led me to believe that LLMs do in fact require quite a lot of structure and guidance to perform tasks reliably and efficiently. Witnessing the external structuring required to mold LLMs to perform our required tasks reliably triggered my own curiosity about the internal structuring of LLMs and other AI models themselves and how this internal structure may be fine-tuned or adjusted to better represent our real world and therefore potentially generate more useful outputs.